
Changing mindset with functional concepts
- Processes, standards and quality
- Technologies
- Others
When I first heard of functional programming (FP) I thought it’s another over-hyped thing that no one needs. I lived in my happy object-oriented world and didn’t think that there is something I should change. It wasn’t until I saw very convincing video where Uncle Bob described why FP is so important.
I decided to give it a shot. I started to use small, not very popular, but very functional (as people described it) JavaScript library. It’s called React.js.
I quickly realized how powerful functional concepts are. We use them all the time without even knowing.
Purity
React is a library for creating HTML views with some desired logic. The main building block is a „component”.
A component accepts data and returns HTML.
An example:
const SomeComponent = ({data}) => {
return (
<div>
<h1>{data.title}</h1>
<p>{data.text}</h1>
</div>
)
}
Note: The code above is a valid JavaScript. It uses JSX syntax extension.
As you can see, it’s very easy to follow the code. The trick is that given the same input this component will always give the same output.
It is possible because SomeComponent doesn’t access any external state and doesn’t call any external APIs. It’s pure and doesn’t have any side-effects. You don’t need to worry that some unexpected magic will happen during this function call.
In FP those functions are called pure functions. They work only on the arguments they accept and don’t access external state.
But what exactly are those side-effects, you may ask. A couple of examples:
- accessing database
- writing to disk
- network communication
- displaying data
- triggering events
Avoiding side-effects is another core concept straight from functional programming.
It’s not possible to write applications that will be all-pure and without side-effects whatsoever. The key is to keep them in one place. Preferably, „on the edges” of the application.
By doing so, you get the two important benefits – composability and simpler tests. As you can imagine it’s extremely easy to test functions like the one in the first example. You just need to provide some parameters and test the output. No need for sophisticated mocking libraries.
As a bonus you get: well-structured code, less problems with refactoring, easier debugging and extendability.
Example of testing using Enzyme library:
it('renders SomeComponent', () => {
const wrapper = shallowRender(
<SomeComponent
data={{title: 'hello', text: 'world'}}
/>
);
expect(wrapper.find('h1')).to.have.length(1);
expect(wrapper.find('p')).to.have.length(1);
});
Pure functions also enable composition. Let’s say you have more data to render and the view is slightly more complicated:
const data = {
menu: [
{link: 'http://netflix.com', title: 'Netflix'},
{link: 'https://www.primevideo.com/', title: 'Amazon Prime'}
// ...
],
title: 'Some Heading',
text: 'Lorem ipsum...'
}
const MenuComponent = ({menu}) => {
const menuHtml = menu.map(menuElement => (
<a href={menuElement.link}>{menuElement.title}</a>
))
return (
<div>
{menuHtml}
</div>
)
}
const SomeComponent = ({data}) => {
return (
<div>
<h1>{data.title}</h1>
<MenuComponent menu={data.menu} /> // passing menu array here
<p>{data.text}</h1>
</div>
)
}
render(
<SomeComponent data={data} />,
document.getElementById('main')
)
Note: Please treat all the code examples in this article as a pseudo-code.
Having two pure functions – MenuComponent and SomeComponent, allows you to mix them together in any way you want. And still, you don’t need to worry about side-effects as those functions don’t have them.
Immutability
What is missing from the above example is data manipulation. In traditional programming, data manipulation is often done by mutating the values.
A simple example:
const doSomethingToTheArray = arr => {
array.push(4) // mutating the original array
}
const anArray = [1, 2, 3]
doSomethingToTheArray(anArray)
// [1, 2, 3, 4]
This pattern can be very dangerous.
Imagine you need to pass down the same array to other functions. And those functions can also mutate this piece of state.
The only way to know for sure where the state is being changed is to follow the code. Sometimes several layers down.
You end up introducing shared mutable state. Some believe it’s the root of all evil (I agree).
Browser events, API calls etc. can happen at unpredictable times. Given that, tracing all mutations of shared state across the application becomes troublesome quickly.
What’s the alternative?
FP introduces the concept of immutability – you cannot change a value which was once created.
const doSomethingToTheArray = arr => {
return array.concat(4) // no mutation, returning new array
}
const anArray = [1, 2, 3]
const newArray = doSomethingToTheArray(anArray) // no mutation
If you don’t mutate any state, you don’t have to deal with concurrency problems.
However in my opinion, there is more important, architectural benefit. The state is being managed in one place so it’s easier to track the changes.
Let’s focus on that.
In React, if you pass the state down the components tree, it can never be reassigned.
So how do you change the state?
The component defining state is responsible for handling all changes. Let’s say you want to modify the state by clicking some button in the child component. To do that, you need to pass down not only the data, but also a handler that is able to change it.
A code example is worth a thousand words, so let’s see how it works.
// a way to define a stateful compnent
const StatefulComponent = React.createClass({
getInitialState () { // defining initial state
return {
data: [1, 2, 3]
}
},
// a handler changing state
changeSomeState (newValue) {
// built-in function to change the state
this.setState(({data}) => {
return {
data: data.concat(newValue)
}
})
},
return (
<div>
<ChildComponent
changeSomeState={this.changeSomeState}
data={this.state.data}
/>
<SomeOtherComponentDiplayingData data={this.state.data} />
<SomeOtherComponentChangingData
changeSomeState={this.changeSomeState}
data={this.state.data}
/>
</div>
)
})
const ChildComponent = ({data, changeSomeState}) => {
return (
<div>
<button onClick={() => {changeSomeState(4)}}>Click</button>
</div>
)
}
StatefulComponent follows the principle I mentioned before – it owns the state and it’s the only place where the state can be changed. ChildComponent is just a puppet that invokes the changeSomeState handler on a button click. It calls a passed function to change the state, but cannot directly modify the state.
See how easy it is to track the state. You immediately know where it is used and what child component uses the handler to modify it.
We know that there is one more component displaying the state (SomeOtherComponentDiplayingData), and one more that changes it (SomeOtherComponentChangingData).
There is almost no cognitive load regarding state management. You just need to look at StatefulComponent to tell what kind of state modifications you can perform.
I once was in a situation when we struggled with state management in the project. It looked similar to this:
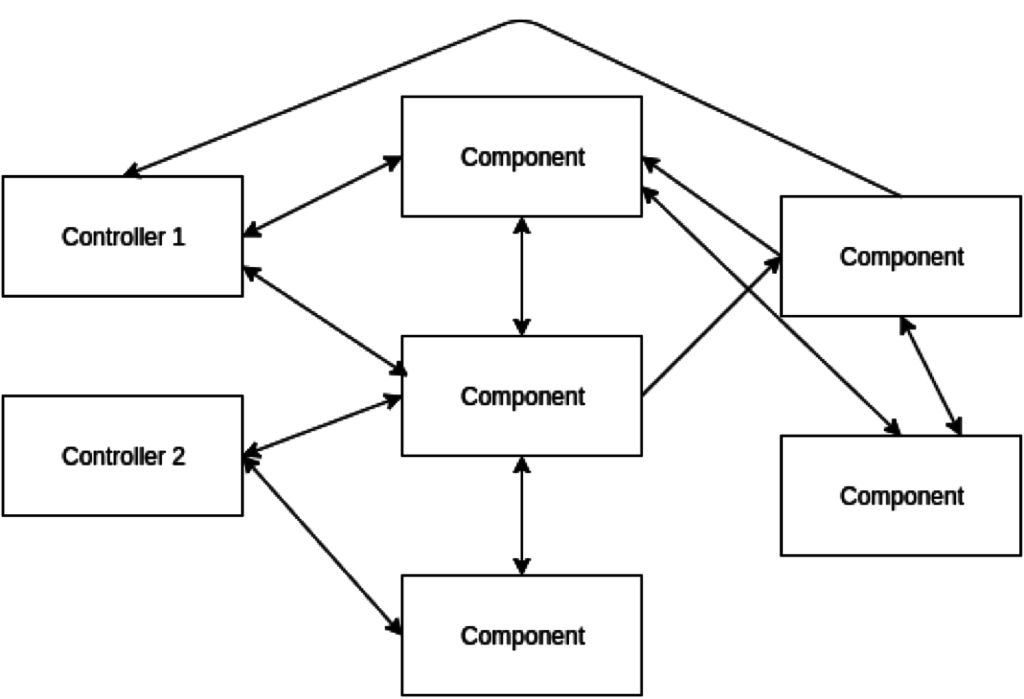
If we had follow the principles described above, it could look like this:
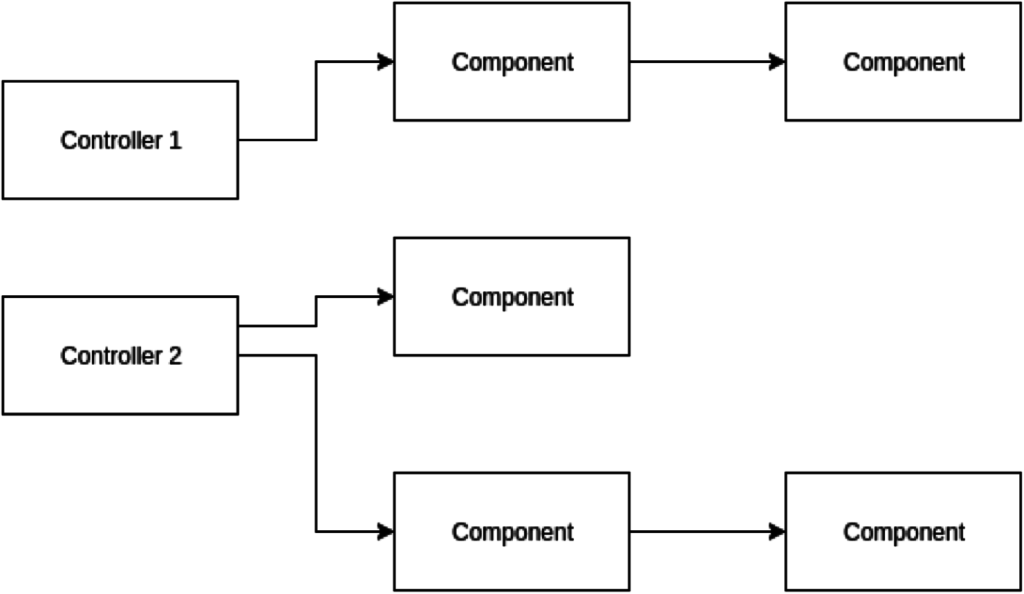
Which one would you prefer?
Redux
When working with frontend code you can help yourself even more by abstracting state management outside the components.
The most popular library that helps with that is Redux.
It’s an implementation of Flux architecture that Facebook people described around the same time React came to life.
The premise is to have a global state container. The state is not kept inside a stateful component but in a global store.
If you want to perform a change state, you need to emit an action. Then, the action is dispatched to the store. The store handles all changes, and then informs all subscribers about new state so they can fetch it and re-render the view.
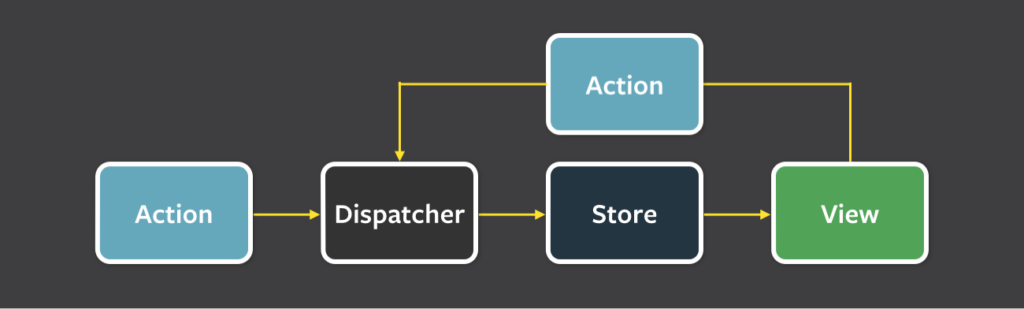
Note: „Redux doesn’t have the concept of a Dispatcher”
Redux is very functional by itself. The „store” parts responsible for state modification are called „reducers”, and they are pure functions that accept some state and an action. They return modified state.
An example from Redux docs:
// todos reducer
function todos(state = [], action) {
// Somehow calculate it...
switch (action.type) {
case 'ADD':
return state.concat(action.payload)
default:
return state
}
return nextState
}
const addTodoAction = {type: 'ADD', payload: 'write a blog post'}
Redux will handle the action by providing the previous state to the todos reducer along with the addTodoAction. After running the reducer, the new state will be returned.
Again, abstracting state management makes it easy to test. You need to provide some state and action. This way you can test any case you can think of without any trouble.
A testing example from Redux docs:
it('should handle ADD_TODO', () => {
const initialState = []
expect(
reducer(initialState, {
type: types.ADD_TODO,
text: 'Run the tests'
})
).toEqual(
[
{
text: 'Run the tests',
completed: false,
id: 0
}
]
)
)}
You might want to try Redux if your state management becomes complicated and you want to introduce some more predictability.
Higher-order functions
Sometimes components need to be decorated with some common logic. An example may be getting user rights to enable/disable some fields.
React allows you to define a wrapper for components that handle those situations.
// component that requires user rights
const WrappedComponent = ({user}) => {
if (user.isAdmin) {
return <AdminStuff />
}
return <RegularStuff />
}
// wrapper function
const withUserRights = Component => React.createClass({
getInitialState () {
return {
user: null
}
}
componentDidMount () {
this.setState({user: getUserData()})
},
render () {
return <Component user={this.state.user} />
}
})
// usage
const WrappedComponentWithUserRights = withUserRights(WrappedComponent)
withUserRights function returns a component that is a higher-order component (HOC). Description of this technique can be found in the advanced techniques section in React docs. But to be honest, it quickly becomes useful.
As described in the docs, HOC is a function that takes a component and returns a new one.
This concept is borrowed from FP where it’s called a higher-order function.
A higher-order function is a function that takes a function as a parameter, returns a function or does both.
The most basic example would be `map()`.
const mapped = [1, 2, 3].map(n => n + 1) // [2, 3, 4]
It’s all about abstraction. map() for example is an abstraction over for loop that is assembling new array. There is less chance of introducing bugs when you use built-in abstractions, such as map(), filter() or forEach(). You can forget about low-level concepts like counter incrementation.
Imagine more complicated (and a little bit exaggerated) chain of functions:
const Wrapped = withSuperFeatureNumber3Enabled(
withFancyHeader(
withUserRights(WrappedComponent)
)
)
Every layer of abstraction in this example encapsulates some common logic. The code becomes clearer and you can see what other programmer had in mind. The code is easy to follow and using composition you get better code reuse.
Summary
There are many techniques originating from FP that you can use on a daily basis. Those are the most basic building blocks of functional programming, but I find them the most useful ones.
Pure functions with no side-effects give you better abstraction and composition. Pair that with immutability and predictable state management and you end up with less error-prone code and less cognitive load.
Higher order functions give you a better abstraction of common logic and play great with pure functions.
I really encourage you to dig deeper, as FP will become even more useful in the future.
If you are looking for sources of knowledge, I recommend reading:
- „So You Want to be a Functional Programmer” by Charles Scalfani
- „Professor Frisby’s Mostly Adequate Guide to Functional Programming”
- „What is Functional Programming?” by Eric Elliott
I often repeat that functional programming is a mindset. The bad thing about mindsets is they are not easy to change. In the case of FP, I think it’s worth it. Just give it five minutes.

