
- Processes, standards and quality
- Technologies
- Others
During one of our last projects we had a small 2-year adventure with Apache CouchDB NoSQL database. Here, I’m going to briefly present its strong points as well as drawbacks.
Background
Why using yet another NoSQL? CouchDB was chosen based on requirements and assumptions in the project. Especially, easy multi-master replication seemed to be attractive in the context of the project, which was supposed to be a distributed document database without any relations and rather unstructured data. Unfortunately, as we were going deeper into the project those assumptions turned out not to be 100% correct, and sometimes using this technology was a bit painful.
Features
What does Apache CouchDB offer?
- RESTful API – actually, there isn’t any other interface than HTTP. To start the machinery you just need to have at least one TCP/IP port free.
- JSON and JavaScript – CouchDB stores and serves JSON documents, as well as uses JavaScript to manipulate them during validation or querying. What is noteworthy you can also attach your favourite scripting language other than JavaScript.
- Schema free – however, you can still define your own per-document validation function.
- Scalability – the manufacturer declares that it works effectively on one machine and through replication can be scaled out to many machines.
- Multi-master asynchronous replication – documents can be bidirectionally replicated to many instances and every instance can simultaneously modify all of them.
- Because of asynchronous and multi-master nature of CouchDB’s replication we also have optimistic locking provided out of the box. CouchDB maintains “_rev” (revision-version) field in every document.
NoSQL in case of CouchDB means that we don’t have neither transactions nor relations maintained by the DB. Also pessimistic locking is not provided. Unfortunately, we had some relations in our data. Handling that was possible but rather hard as everything had to be done manually.
Data organization
CouchDB stores data organized into:
– databases
– documents
All names starting from an underscore are reserved by the system, which uses them for storing it’s metadata – so the actual data is somehow mixed with it. It makes everything uniform and simple since everything is a document. On the other hand, for example you should usually filter out special documents from your query results.
Document validation
Design document is a place where you can define document validation function:
{
"_id": "_design/assets",
"language": "javascript",
"validate_doc_update": "function(newDoc, oldDoc, userCtx) {
if (newDoc.address === undefined) {
throw({forbidden: 'Document must have an address.'});
}";
}
}You should be aware of one thing that documents coming from replication are also validated, so the validation must be the same for all replicating instances. When validation for a single document fails, the replication process simply goes with the next documents. Effectively, the change is silently ignored, leading to hard to find and fix inconsistency.
Querying data
You can’t simply query CouchDB with “dynamic” one. All possible queries should be defined earlier, which can be done also in a “design document”. Such queries are named “views” and are actually B-tree indexes. Those indexes are defined in map/reduces manner, which is shortly discussed here: http://docs.couchdb.org/en/latest/intro/tour.html#running-a-query-using-mapreduce
Having such definition:
{
"_id": "_design/assets",
"views": {
"by_schema_version": {
"map": "function(doc) {
emit(doc.schemaVersion, 123);
}";
}
}
}We can query this:
{ "total_rows": 53, "offset": 0,
"rows": [
{
"id": "a",
"key": 1,
"value": 123
},{
"id": "b",
"key": 2,
"value": 123
}]}You should remember that those indices are updated while querying them. Taking this into consideration, together with fast growth of different views with different parameters (everything must be defined before) it may sometimes cause lags during queries. Especially, in case the great amount of documents has been changed since last index update.
When you need dynamic search queries you can use some layer above CouchDB – such as Lucene or ElasticSearch.
Replication
CouchDB replication was the main reason we used CouchDB. It can be driven extremely easy by “_replicator” special-db running as a separate process and replicating data between two instances. You just need to know urls of both CouchDB instances.
Conflict resolution
The main problem in replication is conflict resolution. Due to the fact that all instances can modify all documents you can sometimes end up with a situation in which two of them change the same document being unaware of a change happened in another location. The following diagram illustrates such a case:
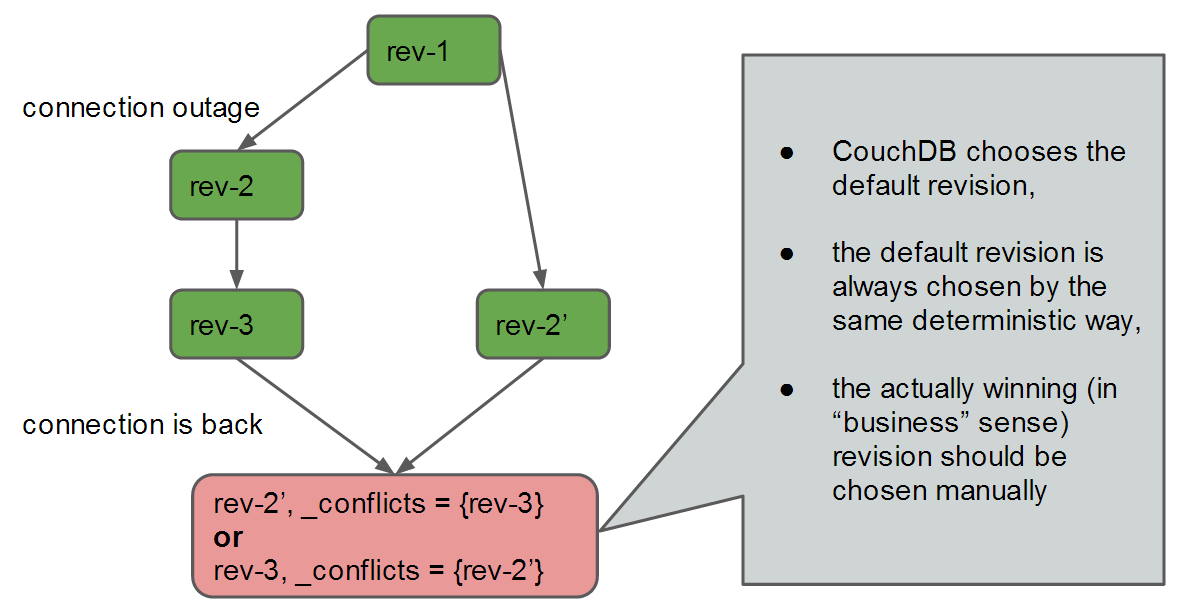
The most problematic situations are when one instance deletes and the other modifies a document. CouchDB doesn’t handle this well, since you can’t check the content of a document that has already been deleted. What’s more, there are a few bugs in this area and metafield holding this information (“_deleted_conflicts”) is undocumented. In case of delete-update conflicts you should either choose “deleted always wins” strategy or introduce your own “deleted” flag to choose the winner in your usual way.
Maintenance
CouchDB doesn’t need too much attention from its user. It’s rather stable, and crashes only in critical situations (out of disk space etc.). However, since CouchDB normally runs many processes, sometimes after such a crash you can get not fully dead DB. It can be annoying as you need to manually find all orphaned processes and kill them. Using default start/stop scripts can sometimes end up in two instances running concurrently and logging errors.
When you have much modification activity, indices can grow fast, sometimes taking even more disk space than the actual data. To avoid this you should also consider scheduling “compaction” of databases.
When everything goes well, you can find all requests and investigate what happened by using logs. Unfortunately, activity coming from batch updates (and thus from the replication which uses batch requests) isn’t clearly marked and tracing it can be sometimes hard. Also logs from crashes and unhandled situations won’t tell anything to anybody inexperienced with Erlang programming language.
Conclusion
CouchDB itself seems to be simple and easy to use document store. It offers a few very useful, out of the box features such as optimistic locking and easy replication. Since it uses only JSON and HTTP, it can be used directly from browser JavaScript.
Good example of usage for CouchDB is when you don’t change document data too often and you can define all possible queries in advance. In some applications it has also a few drawbacks which I tried to point out.
What are your experiences with production-grade systems based on document databases?
External links & further reading:
[1] http://couchdb.apache.org/
[2] http://pouchdb.com/ – PouchDB, in-browser simple document database that can be synchronized with CouchDB instance.
It seems to be only a gadget but maybe somebody can find it useful.
[3] http://hibernate.org/ogm/ – Hibernate OGM integration with CouchDB. Unfortunately, when we were starting our project there wasn’t mature and reliable CouchDB client, so we had to write our own. OGM is going to have full support for CouchDB, so probably it will be quite useful.
