
ElasticSearch and database through river – scalable data store and search engine platform
- Processes, standards and quality
- Technologies
- Others
Scalable data store and search platform used to be a challenge requiring tens of hours spent on installation and configuration. After that it finally made things work together with required performance. How often do we develop solutions containing database storage with number of requirements commonly available in relational or non relational databases, also having high expectations on searching, frequently difficult or even impossible to meet by most of database engines?
Usually, we want to use only a single type of database focusing on finding as suitable one as we can, but it almost always ends with complex tuning and customization. To avoid it, we should realize that we can use database for fulfilling data store requirements and separate search engine to handle search expectations. In my example I’ll use MongoDB and Elasticsearch with data synchronization through river plugin. Let’s see what we can do during a coffee break, assuming we have a Linux Ubuntu 14.0 based machine with java.
One important thing before we start is to check which versions are compatible for use, what can be done on mongoDB river page (https://github.com/richardwilly98/elasticsearch-river-mongodb).
1. MongoDB
MongoDB is an open-source document database with built in replication, high availability, auto-sharding and map/reduce mechanisms. That sounds good as a scalable data store for our environment.
After several commands:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10 echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list sudo apt-get update sudo apt-get install -y mongodb-org=2.6.5 mongodb-org-server=2.6.5 mongodb-org-shell=2.6.5 mongodb-org-mongos=2.6.5 mongodb-org-tools=2.6.5
followed by mongoDB config change with replset value, and after mongod service restart, we’ve got MongoDB on board and running. Much work in short time – 4 minutes in my case.
2. ElasticSearch
Elasticsearch is a powerful open source, real-time search and analytics engine, designed from the ground up to be used in distributed environments with reliability and scalability as a must have. Looks great as a search engine for our platform.
After several commands:
wget -qO - https://packages.elasticsearch.org/GPG-KEY-elasticsearch | sudo apt-key add – sudo add-apt-repository "deb http://packages.elasticsearch.org/elasticsearch/1.3/debian stable main"; sudo apt-get update && sudo apt-get –y install elasticsearch=1.3.5 sudo update-rc.d elasticsearch defaults 95 10 sudo /etc/init.d/elasticsearch start
ElasticSearch is on board and running – 3 minutes in my case. It’s recommended to use the second machine to avoid sharing resources, but for test deployments a single one is good enough.
3. MongoDB river plugin for ES
Elasticsearch provides ability to enhance the basic functionality by plugins, which are easy to use and develop. They can be used for analysis, discovery, monitoring, data synchronization and many others. Rivers is a group of plugins used for data synchronization between database and elasticsearch. The most known examples are:
- Supported by ES: CouchDB, RabbitMQ, Twitter and Wikipedia
- Supported by community: MongoDB, Amazon S3, IMAP/POP3, Redis, GitHub, Dropbox
In our case we will use MongoDB river plugin for data synchronization. Once more, after several commands:
./plugin -install elasticsearch/elasticsearch-mapper-attachments/2.3.2 ./plugin --install com.github.richardwilly98.elasticsearch/elasticsearch-river-mongodb/2.0.4 service elasticsearch restart
followed by river configuration in Elasticsearch:
curl -XPUT „localhost:9200/_river/river/_meta” -d ’
{"type": "mongodb",
"mongodb": {
"servers": [{ "host": "127.0.0.1", "port": 27017 }],
"db": "rivertest",
"collection": "rivers";
},
"index": {
"name": "riverindex",
"type": "river";
}
}'
we’ve got ElasticSearch automatically synchronizing data with MongoDB – 2 minutes in my case.
Ok, we’ve got 1 minute left and the last sip of coffee, so it’s time to test our solution. Let’s load some data to mongoDB:
mongo
> use rivertest
> var p = {Name: "MongoDB River Plugin"}
> db.rivers.save(p)
What have we forgotten about? Where is our database with its configuration? How will the data be synchronized with elasticsearch if there is no index and mapping between collections? Let’s check what we’ve got.
When document is inserted to MongoDB, database is created (if it doesn’t exist), along with schema for that particular record. Then, our data is stored. When more data comes in, the schema is updated. Everything with default configuration, but it’s nice for the beginning. If someone doesn’t believe, just find the data in database:
{ "_id" : ObjectId("549299079f9c04449afad64c"), "Name" : "MongoDB River Plugin" }If we want to search for it in elasticsearch – nothing easier! Just open a web browser or use curl and search under localhost:9200/riverindex address:
curl 'localhost:9200/riverindex/_search?pretty'
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [{
"_index" : "riverindex",
"_type" : "river",
"_id" : "549299079f9c04449afad64c",
"_score" : 1.0,
"_source":{"Name":"MongoDB River Plugin","_id":"549299079f9c04449afad64c"}
} ]
}
}
After inserting document in MongoDB configured as replica set, it is also stored in oplog collection.The mentioned collection is operations log configured as capped collection, which keeps a rolling record of all operations that modify the data stored in databases. River plugin monitors this collection and forwards new operations to elasticsearch according to its configuration. That means that all insert, update and delete operations are forwarded to elasticsearch automatically. In our case, river named river synchronizes data from collection rivers in rivertest database with river type in riverindex index. Missing index with default configuration was created automatically while indexing data in ES.
We can easily check what we have in ES using head plugin, that can be installed with the help of command:
./plugin -install mobz/elasticsearch-head
Some elasticsearch plugins provide web interface that can be reached using endpoint /_plugin:
http://localhost:9200/_plugin/river-mongodb/
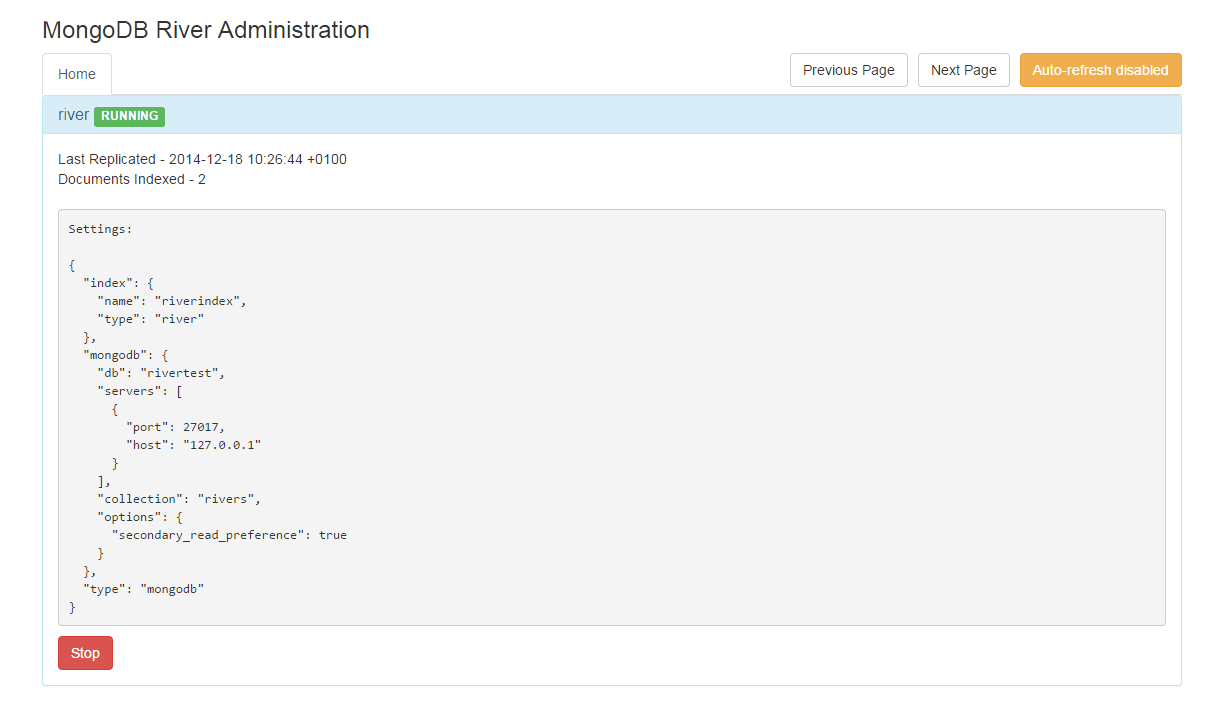
http://localhost:9200/_plugin/head/

Summarizing, we have MongoDB configured as replica set, Elasticsearch with River that pulls data from database to index, and finally everything is prepared for sharding and replication. Standard software configuration of every part of our platform is optimized for initial use. There is no equation or performance matrix showing how much load will be handled depending on configuration. It also strongly depends on hardware and JVM configuration. Recommended practise is to start with initial software and common hardware configuration. Then, verify your solution against requirements and make changes only if you are not satisfied with result.
Next time, I’m going to present how to easily scale this platform by creating mongoDB replica set with a few members and Elasticsearch cluster build of several nodes, both with load balancing, sharding and replication, highly available and resistant for data loss. New post coming soon.
4. Resources:
- http://docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/
- http://docs.mongodb.org/manual/tutorial/deploy-replica-set/
- http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/setup-repositories.html
- http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/setup-service.html
- https://github.com/richardwilly98/elasticsearch-river-mongodb/