
Moving data processing to the cloud – part 2 – Azure Data Lake
- Processes, standards and quality
- Technologies
- Others
The main questions addressed in the first part of the article are whether the task of moving business processes to the cloud is really that difficult and does it affect all of the company’s systems. I have demonstrated that it is easier than you would have thought by dealing with the problem posed by the online store company. In this hypothetical situation, the company asked its team of programmers to deliver new reports required to analyse the company’s stock availability. The previous part of the article attempts to show how to create a pipeline which fetches, processes and stores the data in the on-premise database. In this part, I will focus on presenting how to implement the reports.
The dev team has been asked to deliver a couple of reports to monitor stock availability and requisition. It sounds easy, but the company which offers a huge variety of items online will have a gargantuan amount of data. It requires a computation power to process which often is not available on the in-house servers. The team decided to use Azure Data Lake Analytics to implement the solution.
Azure Data Lake Analytics
In short, it can be said that Azure Data Lake Analytics (later referred to as ADLA) is a service which allows for processing big datasets on the distributed environment in the cloud. It uses . Everyone who is familiar with the SQL language will be able to develop functionality in ADLA as it uses the language’s variation named U-SQL. [1]
Let’s analyse a daily report which is currently calculated by using the database procedure and will be moved to the cloud.
The daily statistics calculate the total amount, net and gross price for each product type. The U-SQL script below fulfils the requirement. It can be noticed that the U-SQL language combines SQL and C# language.
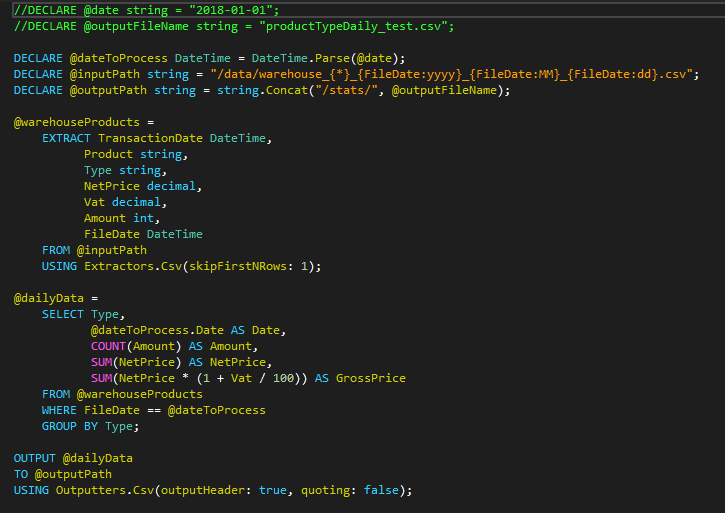
Script to perform daily reports
The first two commented variables come from Azure Data Factory as parameters so they are used only for testing purposes. We can split the script into four sections: variable declaration, data extraction, data calculation, and saving the result.
In the first section, the variables are declared. What makes it interesting is the pattern used in the input path. The sample input file is named warehouse_001_2018_01_01.csv. The name contains the warehouse number (001) and date of the summary (2018-01-01). The input path contains logic which says that it is interested in all files which start with the warehouse phrase, no matter of which number. Additionally, it says that the last section is parsed to the FileDate variable which becomes an additional column in the data set.
The second section of the script is a simple extractor. In this place, it is necessary to declare all the columns from the flat file plus additional columns which were created in the input path (like FileDate). Moreover, each column needs to specify the type of data. U-SQL language uses .Net types. The extractor is the csv extractor in which it is specified to skip the first row as the files contain headers.
In the third section, the report logic is applied. There would be nothing extraordinary in this query if the WHERE clause was not there. It may look easy – a comparison of two variables. What makes it special is the fact that the column used in the comparison is built from the file path. This is very useful for the performance reasons as only the files which will fulfil the condition will be loaded and processed.
Finally, the last section contains an action of saving the result to the flat file.
Azure Data Lake Analytics offers an easy-to-analyse summary of the script execution.
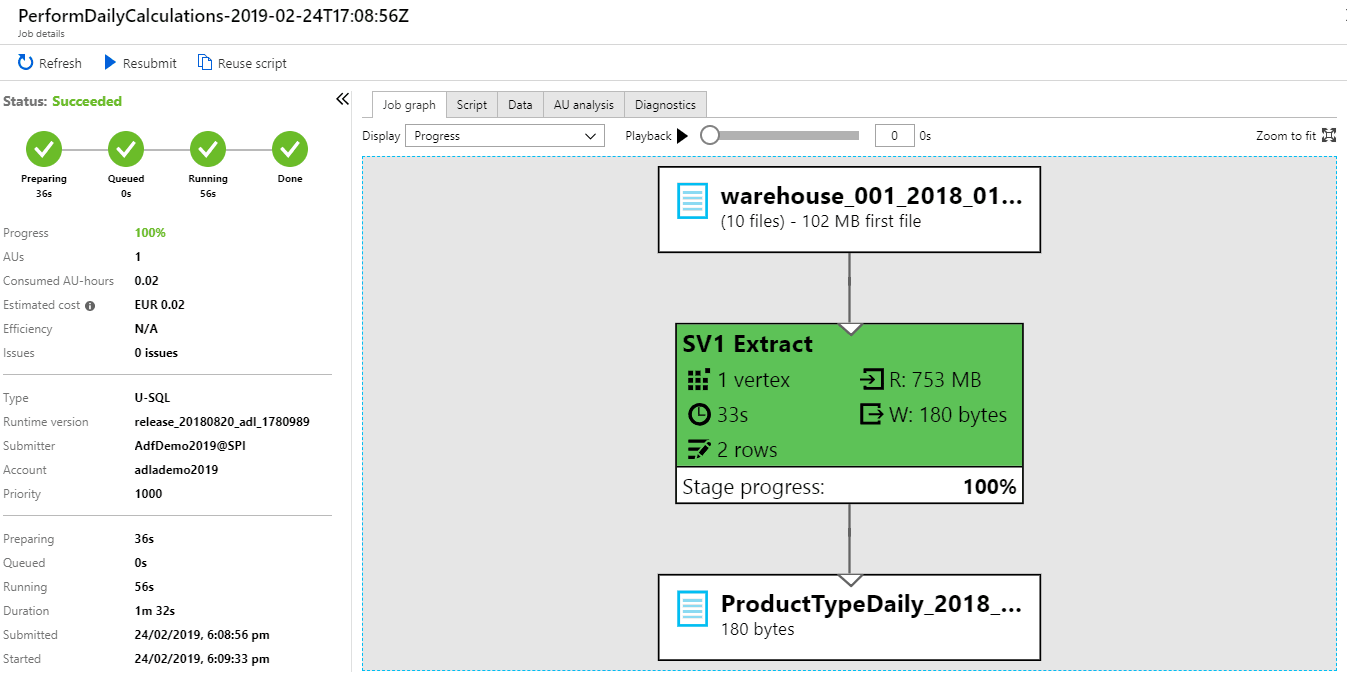
Daily Azure Data Lake Analytics script successful execution
Thanks to the screenshot of the execution you can see that the process took a little more than 1.5 minutes and processed 10 files (as the rest were filtered) and 753 MB of data, and that it costed 0.02 Euro. It was run only on 1 AU. The more extreme case will be examined for a yearly summary.
The successful data fetch, ADLA script execution, and save results to the on-premise database mean that the team of programmers succeeded in creating their first report. The next one is more complicated as it requires more data to process. Or… is it?

Successful pass of the daily pipeline
The yearly report requires to process all the raw files from the whole year as it focuses directly on the product and not on its? type as in the case of a daily report (already calculated aggregation cannot be reused). It requires to calculate which was the most popular product in each warehouse and what its percentage share in all of the warehouse’s sales was.
The dev team quickly develops a new pipeline which is simpler than a daily pipeline, because it does not require to fetch data from the FTP server and all the connections are already created.

Pipeline to calculate yearly reports
The U-SQL script has the same structure as the script presented before. The interesting fact used here is that the warehouse number is not present in the file itself, but it is required to perform required aggregations. Similarly to the FileDate variable, it is taken directly from the file name.
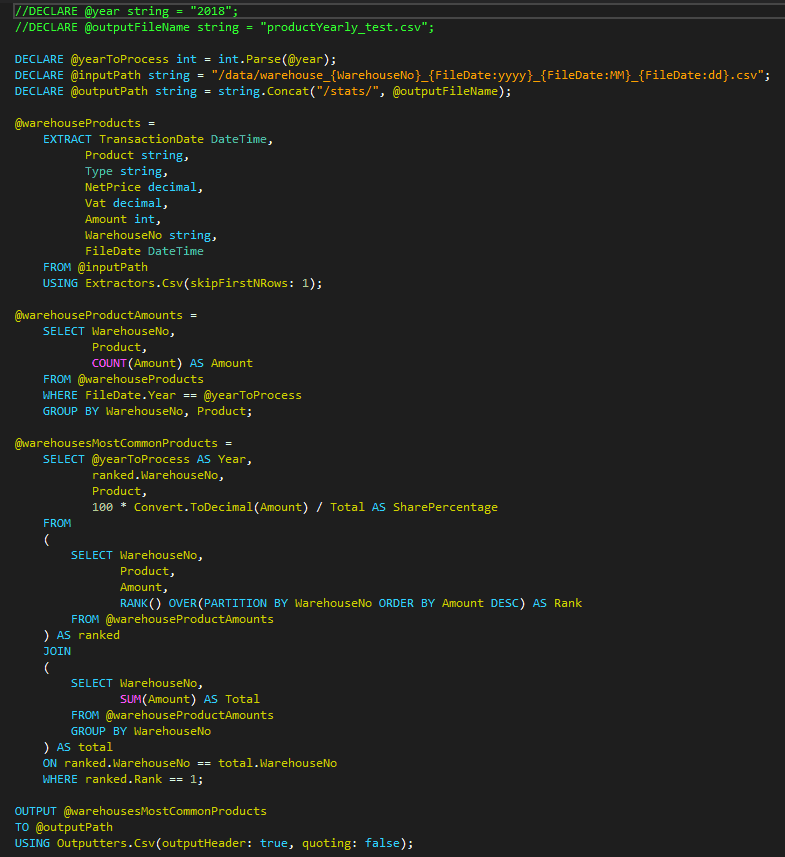
Script to calculate yearly statistics
The development team runs the pipeline to perform calculations. The Azure Data Lake Analytics comes with following summary:
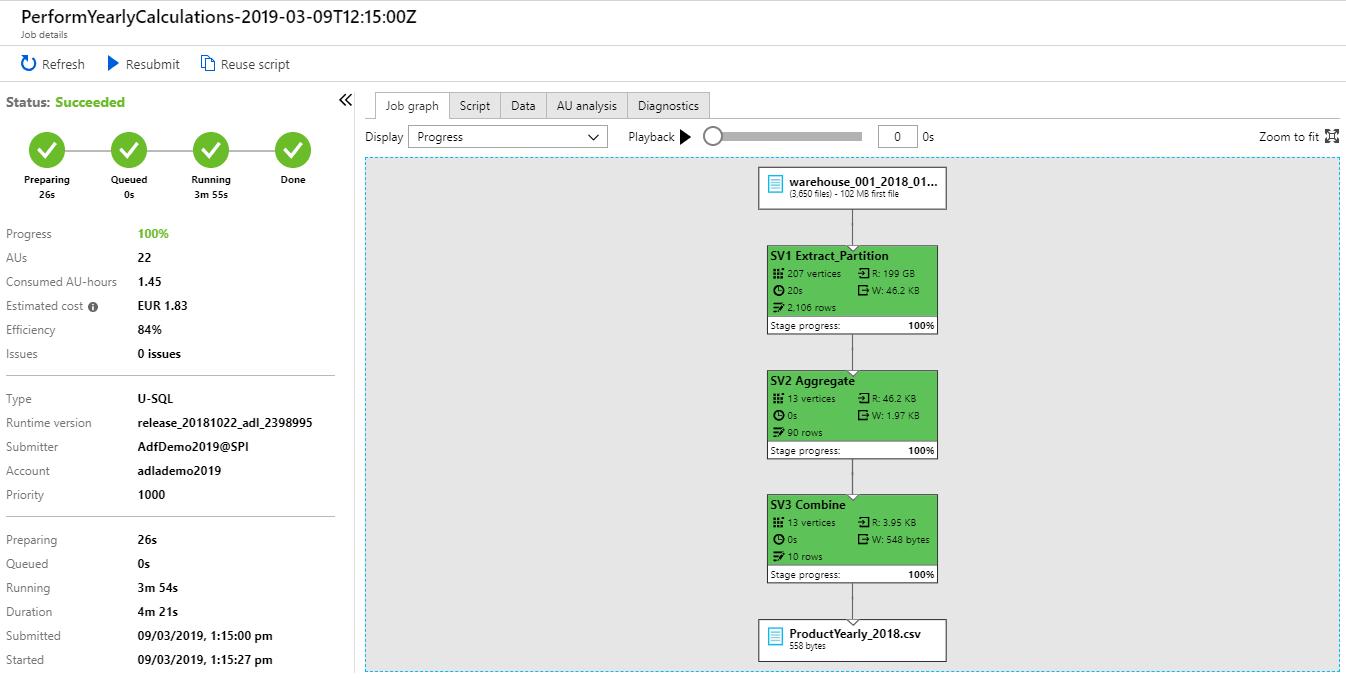
Daily Azure Data Lake Analytics yearly script successful execution
From the summary above it can be read that the 3650 files were analysed and almost 200 GB of data. It took 4 minutes and costed 1.83 Euro. It was run on 22 AUs. The question is whether it can be run faster or cheaper. The ADLA gives the possibility to analyse if it is better to increase or decrease number of AUs during the next run.

Azure Data Lake Analytics AU analysis
The AU analysis tab presents the optimal configuration for Balanced and Fast run and compares it to Actual execution. According to ADLA the optimal number of AUs is 114 for Balanced run and 115 for Fast run. So, for one additional Euro about three minutes can be cut from the execution time. The cheapest configuration to run is 1 AU, where efficiency is 99% for the obvious reason. It will save 30 eurocents in comparison to the Actual run but it would take more than one hour to execute.
Solution Maintenance
What about this solution maintenance? The Azure Data Lake Analytics scripts can be stored in the Microsoft Visual Studio project and solution, and versioned on any version control system. The Azure Data Factory is not worse in this matter. It can be connected to, for example, the Git repository where all the changes are versioned. It also allows for changing between branches so new updates can be developed and tested on the separate environment from production. Simple merge features a branch to master and execute the publish process through ADF to deploy a new version of the code.
What about changes in the process? Let’s analyse the situation where the FTP server is replaced by REST API. In the old solution based on the Windows Service, the application needs to be rewritten to modify the way how the source data is fetched. In ADF solution, because of its modular nature, the only change which is required is to replace the source of the data in Lookup activity from flat file to REST resource. It can be tested on the branch and when ready published to the production environment.
Summary
Hopefully, this article has shown that creating a cloud-based solution does not have to be difficult and does not mean that every system and every process need to be moved at once and create a huge business risk for the company’s IT systems. If the company decides to invest in cloud solutions, the people responsible for the systems can move it step by step, simultaneously reducing the risk of failure.
[1] https://azure.microsoft.com/en-us/services/data-lake-analytics/

