- Processes, standards and quality
- Technologies
- Others
Have you ever written a program with such a complex algorithm that despite of using all processor cores the implementation wasn’t efficient enough? If yes, this is the moment you should consider using a more efficient device than CPU.
In this situation modern graphic cards allowing the so called GPGPU (General-Purpose computing on Graphics Processing Units) come with a help. Despite the fact that a single processing unit on graphic card is not equal to one CPU core, there’s strength in numbers.
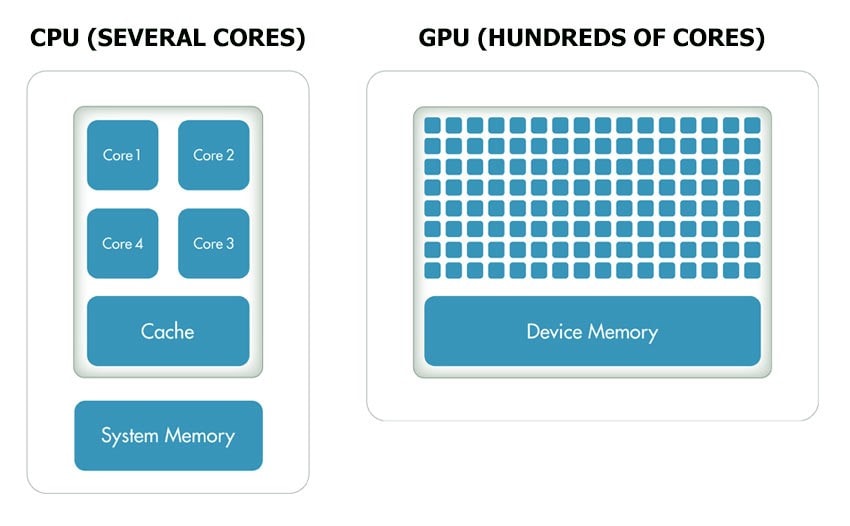
Picture 1. Comparison of CPU and GPU architecture.
Fortunately, the use of the GPU to do calculations in .NET is much simpler than it might seem at first. Cudafy.NET library allows us to convert code written in C# or VB to the one understandable for devices supporting OpenCL or Nvidia CUDA. The majority of code written with the use of library can be converted both to OpenCL code and using CUDA framework. However, there are functionalities that are available only in OpenCL and the ones that run only on Nvidia devices that use CUDA framework. Regarding the universality of the devices supporting OpenCL, further in the article, I will present code that can be launched on devices that support OpenCL (AMD and Nvidia graphic cards as well as Intel and AMD processors).
So much for the introduction. It is time to create a working program that uses GPU to make calculations. Game of Life by John Conway is the program we are going to write. I would like to point out that the code is not optimized and its task is to showcase how easy it is to write code that can be executed on the GPU using Cudafy.NET.
Description of algorithm:
Game of Life is performed on an unlimited, in terms of size, 2D platform, filled with square cells. A cell can be dead or alive. Each of cells interacts with 8 adjacent cells.
At each step in time, the following transitions occur:
- Any live cell with fewer than two live neighbours dies.
- Any live cell with two or three live neighbours lives on.
- Any live cell with more than three live neighbours dies.
- Any dead cell with exactly three live neighbours becomes a live cell.
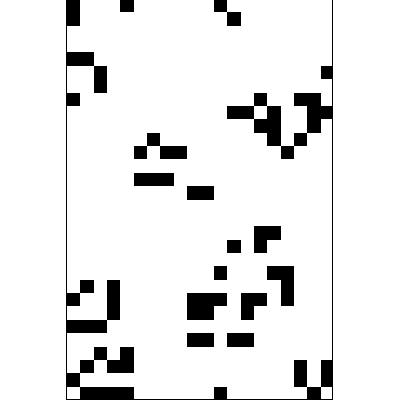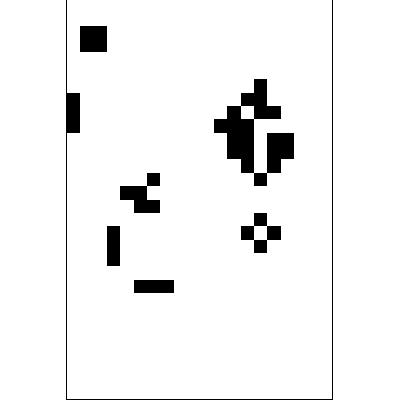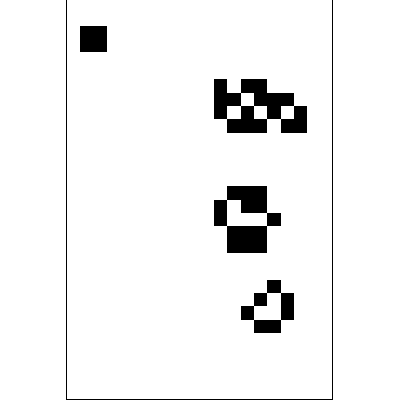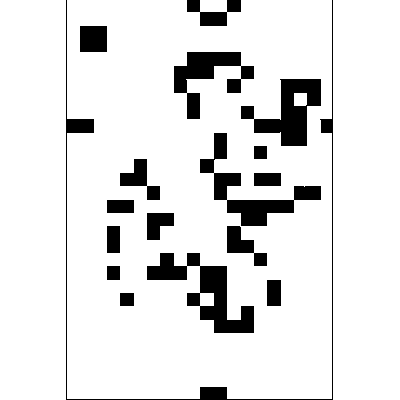
Before the game starts, the board should be initiated. It is generated by applying the above rules simultaneously to every cell on the board – births and deaths occur simultaneously.
Creating the program:
- Creating the project
- Adding a library to the project
- First lines of code
- Generating the initial state of the board
- Choosing the compatible device
- GPU memory pointers and memory allocation
- Copying data to GPU
- Implementation of game algorithm for GPU
- Loading module to the GPU memory
- Calling code on GPU
- Downloading data from GPU
- Source code of an application and presentation of operating
- Appendix: What we should take into consideration when choosing algorithmConsider the following questions by selecting the algorithm for the application using GPGPU:
- The algorithm should allow a high level of parallelization, so that the calculations can be divided into multiple independent tasks. The code written in OpenCL and executed on graphic card processors runs efficiently when there is a lot of tasks performed simultaneously.
- Minimise the usage of memory. Graphic processors have a very high computational efficiency, which means that the performance of most of the code is restricted by memory efficiency.
- Transferring data to or from graphic cards memory is expensive. The highest efficiency is achieved for large data sets.
- Your program will run much faster if you allocate memory on the device using OpenCL. Just copy data to the device memory, perform as many calculations on that data as possible, and then copy them from your device - as opposed to multiple execution of the cycle upload data – calculate – download the results.
- Whenever possible, use OpenCL built-in functionalities. A well optimized code will be generated for those functions.
- Local storage is multiple times faster than the global memory, but unlike the global memory it is available only for a group of threads included in one block. Try to use it in your programs. Private memory is even much faster than local memory, but it is available only for a single thread.
- In order to find the size of the block which enables obtaining maximum efficiency, it will be necessary to experiment with this value.
- All the threads running on GPU must perform the same code. As a result, when the conditional statement is executed, all threads execute both branches, but the result of incorrect branch is disabled. The best solution is to avoid the conditional statements if and switch - they should be replaced with operator z? x: y, if possible.
We start with creating new console application project in C# language using .NET 4 in Visual Studio.
Next, we add a DLL of a downloaded Cudafy.NET library to project references. We can do that using the project site https://cudafy.codeplex.com/ or NuGet. If we aren’t sure whether our equipment is compatible with the program, we can download, form the project site, files that allow to perform compliance test on our computer.
Now, we are ready to begin writing our simple application.
We start by adding namespace, necessary to use Cudyfy.NET.
using Cudafy; using Cudafy.Host; using Cudafy.Translator;
Listing 3.1. Necessary namespaces for Cudafy.NET library.
The state of the project after this step is shown in the image below.
Picture 3. Initial state of the project and installation of Cudafy.NET by Nuget.
Before we are able to write code executed on GPU, it is necessary to generate our input. For this purpose, we write function, which assigns state (dead or alive) to the cells across the board at random positions.
private void GenerateInputData(byte[,] data)
{
var randomGen = new Random();
for (int x = 0; x < data.GetLength(0); x++)
{
for (int y = 0; y < data.GetLength(1); y++)
{
data[x, y] = (byte)randomGen.Next(2);
}
}
}
Listing 4.1. Generating the initial state of the game.
The next step we have to take is choosing the one device that we will use to perform calculations among all installed ones that support OpenCL. Function argument is the type of device we are looking for in a user's system - in our case it will be eGPUType.OpenCL. Depending on the type, we select the appropriate target language for translator module, which will translate our .NET code to object code in OpenCL. Using GetDevicesProperties function we download information regarding available devices of a selected type. If system has at least one compatible device, it will choose the first one on the list.
private GPGPU GetGPGPUDevice(eGPUType type)
{
CudafyModes.Target = type;
CudafyTranslator.Language = (CudafyModes.Target == eGPUType.OpenCL)
? eLanguage.OpenCL
: eLanguage.Cuda;
GPGPUProperties[] compatibleDevices =
CudafyHost.GetDeviceProperties(CudafyModes.Target, true).ToArray();
if (!compatibleDevices.Any())
{
Console.WriteLine(
"Error: No devices supporting OpenCL. Check if you have latest
drivers installed.");
return null;
}
GPGPUProperties selectedDevice = compatibleDevices[0];
if (selectedDevice == null)
return null;
CudafyModes.DeviceId = selectedDevice.DeviceId;
Console.WriteLine(
"Selected device id :{0} \r\n Name: '{2}'\r\n Platform: '{1}'",
selectedDevice.DeviceId,
selectedDevice.PlatformName.Trim(),
selectedDevice.Name.Trim());
return CudafyHost.GetDevice(CudafyModes.Target, CudafyModes.DeviceId);
}
Listing 5.1. Function chooses a device that will perform the OpenCL object code.
Since the GPU has its own memory and isn’t able to access the data in the RAM on your computer, it is necessary to copy the data to the GPU memory on which we will operate. For this purpose we create variables, which will provide references to areas in the global GPU memory.
private byte[,] _devInputData; private byte[,] _devOutputData;
Listing 6.1. References to areas in the global GPGPU memory.
Although these variables look like ordinary arrays, code executing on the CPU won’t have access to their content. The next step would be the allocation of memory areas to which these variables are accounted as references.
private void AllocateMemoryOnGPGPU(Size boardSize)
{
_devInputData = _gpgpu.Allocate(boardSize.Width, boardSize.Height);
_devOutputData = _gpgpu.Allocate(boardSize.Width, boardSize.Height);
}
Listing 6.2. Allocation of GPU memory areas.
BoardSize argument contains the dimensions of the board and is dependent on the user's screen size. The initial state of each cell will be located in _devInputData. After making calculations the output will be saved in _devOutputData.
Once we have made memory allocation, we can copy the data representing the initial state of the game from RAM to graphic memory.
_gpgpu.CopyToDevice(inputData, _devInputData);
Listing 7.1. Copying data from RAM to global GPU memory.
The code dedicated to a specific task with the use of GPU, which is converted into a language understood by the device, is called module by the creators of Cudafy.NET. This is usually a class having a Launch function expecting a GThread object as a first argument, which allows an access to information on both the position of the current thread in the block, as well as the position of this block in the grid (set of blocks). Results of the calculation depend on those values. Launch function should be marked with a specific attribute, which means that a given function has to be converted to a global CUDA C or OpenCL function. Attributes added to arguments determine in which address space data is saved.
public static class GameOfLifeModule
{
[Cudafy(eCudafyType.Global)]
public static void Launch(GThread thread,
[CudafyAddressSpace(eCudafyAddressSpace.Global)] byte[,] inputData,
[CudafyAddressSpace(eCudafyAddressSpace.Private)] int width,
[CudafyAddressSpace(eCudafyAddressSpace.Private)] int height,
[CudafyAddressSpace(eCudafyAddressSpace.Global)] byte[,] resultData)
{
byte[,] cache = thread.AllocateShared("cache", 16, 16);
// Calculate position in array.
int x = thread.blockIdx.x * thread.blockDim.x + thread.threadIdx.x -
(thread.blockIdx.x * 2) - 1;
int y = thread.blockIdx.y * thread.blockDim.y + thread.threadIdx.y -
(thread.blockIdx.y * 2) - 1;
int cellInCacheX = thread.threadIdx.x;
int cellInCacheY = thread.threadIdx.y;
bool isBoardCell = false;
byte cellValue = 0;
if (x >= 0 && y >= 0 && x < width && y < height)
{
cellValue = inputData[x, y];
isBoardCell = true;
}
// Fill cache cells that will be processed by threads in this block.
cache[cellInCacheX, cellInCacheY] = cellValue;
// Wait until all threads in block finish loading data to shared array.
thread.SyncThreads();
if (isBoardCell &&
cellInCacheX > 0 && cellInCacheX < 15 &&
cellInCacheY > 0 && cellInCacheY < 15)
{
byte aliveCells = CountAliveCells(cellInCacheX, cellInCacheY, cache);
resultData[x, y] = (byte)(aliveCells == 3 || (aliveCells == 2 &&
cellValue != 0) ? 1 : 0);
}
}
// Indicates to compiler that it should convert it to OpenCL or CUDA function.
[CudafyAttribute(eCudafyType.Device)]
// Forces function inlinning.
[CudafyInline(eCudafyInlineMode.Force)]
public static byte CountAliveCells(
int x, int y,
[CudafyAddressSpace(eCudafyAddressSpace.Shared)] byte[,] data)
{
return (byte)(data[x-1, y-1] + data[x, y-1] + data[x+1, y-1] +
data[x-1, y ] + data[x+1, y ] +
data[x-1, y+1] + data[x, y+1] + data[x+1, y+1]);
}
}
Listing 8.1. Game of Life implementation that will be converted to OpenCL by Cudafy .NET.
Before it will be possible to run code on GPU, the code module must be converted to OpenCL. It would be pointless to execute this conversion every time the module is downloaded. For this reason, we do so only if the code has changed or a file with serialized module is missing.
_module = CudafyModule.TryDeserialize(ModuleName);
if (_module == null || !_module.TryVerifyChecksums())
{
_module = CudafyTranslator.Cudafy(eArchitecture.OpenCL, typeof(GameOfLifeModule));
_module.Name = ModuleName;
_module.Serialize(ModuleName);
}
_gpgpu.LoadModule(_module);
Listing 9.1. Deserialization, serialization and loading the module to GPU memory.
To initiate previously created module, we have to invoke Launch function of an object representing our GPU. This function has a lot of overloaded versions that enable start of modules with as many as 15 arguments. GridSize and blockSize arguments determine the total number of executions of this module, as well as about the number of simultaneous executions. In this case, the dimensions of the block are set to 16 x 16, which means that the state is calculated simultaneously for 256 cells on the board by 256 computing units. Value of gridSize argument is dependent on the size of the processed data and a block. Another argument is an action complementary to code which we want to invoke on GPU. Remaining arguments are required by the above-presented action.
private void LaunchGameOfLifeModule(dim3 gridSize, dim3 blockSize, Size boardSize)
{
_gpgpu.Launch(
gridSize,
blockSize,
GameOfLifeModule.Launch,
_devInputData,
boardSize.Width,
boardSize.Height,
_devOutputData);
}
Listing 10.1. Function initiating the execution of Game of Life module on GPU.
As the results of calculations are stored in the GPU memory, they must be copied to RAM before we can present them to the user. Downloading data is as easy as uploading them. In order to download the resulting data only one line of code is needed:
_gpgpu.CopyFromDevice(_devOutputData, tempBuffer);
Listing 11.1. Copying data from GPU to RAM.
_devOutputData variable is a pointer to memory allocated in global GPU memory and tempBuffer is an array in a computer RAM. It is important that the area of allocated memory, to which the pointer refers, and the size of tempBuffer are equal.
If you are curious how the ready application looks like, watch this video. Source code
of the application can be found here.